 daily dose of Piefke 3000 – in glittery English.")
{kind=link}

The Visual Language Research Corpus (VLRC): an annotated corpus of comics from Asia, Europe, and the United States. (Via visuallanguagelab.com, via data-is-plural.com.)
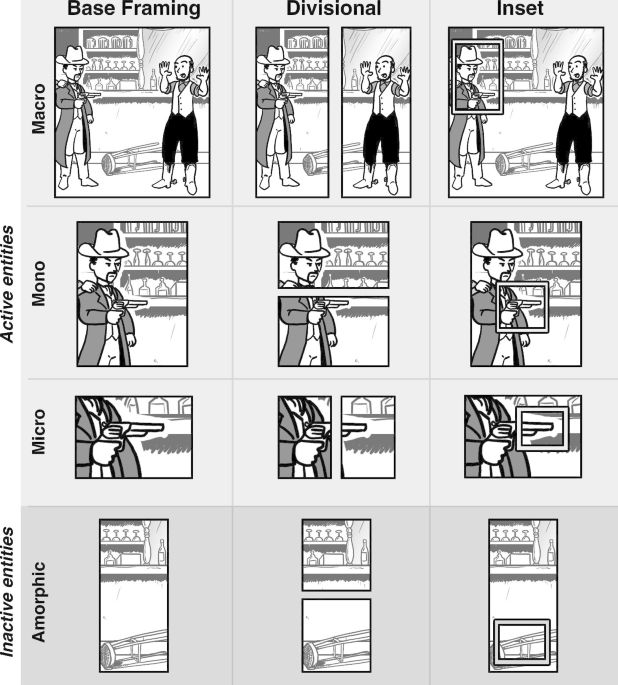
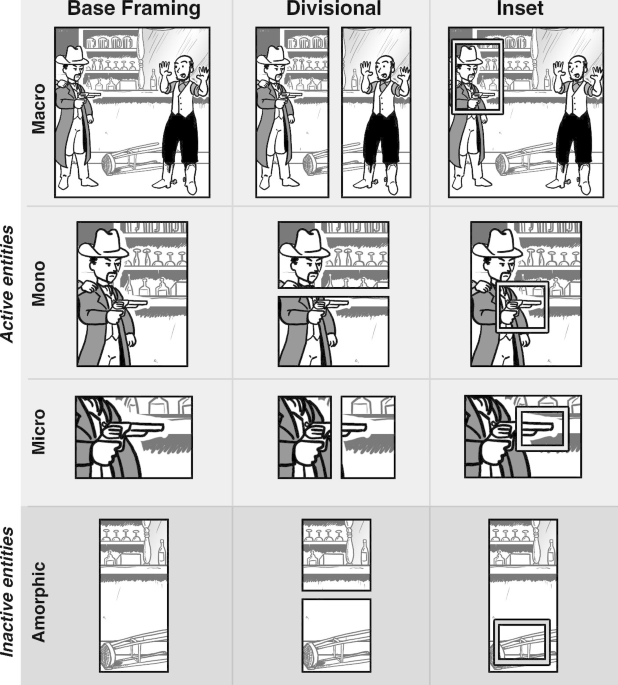
The Visual Language Research Corpus (VLRC) is a dataset of annotations of 376 stories from comics from the United States, northwestern Europe, and East Asia, along with analysis of the complete 10 year run of the Calvin and Hobbes comic strip. Comics were annotated using 254 constructs from Visual Language Theory, a framework focusing on the linguistic and cognitive structures involved in visual and multimodal information. These annotations include analysis of panel’s attentional framing structure and filmic shot scale, the situational changes across panels, page layouts, multimodality, visual morphology, and path structure.
{kind=link}